Compte rendu de réunion de l'ARC TOLERE
INRIA Rocquencourt, le 12-14 avril 2000
Participants
Résultats des recherches de Catalin et d'Alain sur l'ordonnancement
d'un algorithme sur une architecture multicomposants, avec prise en compte
des pannes des processeurs et des média de communication
Un placement d'un algorithme, donné comme un graphe flot des données,
sur une architecture multicomposants qui modélise le problème
d'exécution tolérante aux pannes comprend plusieurs répliques
de chaque opération sur des processeurs distincts et plusieurs répliques
de chaque dépendence de données sur plusieurs média
distincts, même avec du routage si le graphe n'est pas complètement
connecté. Les contraintes sur un tel placement sont telles qu'une
opération ne peut pas être exécutée si elle
n'a pas reçu toutes les données des opérations qui
la précèdent. Cela implique qu'au moins une des opérations
qui la précédent doit être terminée avant la
date de début d'exécution de notre opération et que
les données de l'opération précédente ont été
transmises par un média au processeur sur lequel l'opération
successeur est placée.
L'apparition d'une panne est modélisée par l'élimination
d'une partie des processeurs et média ; ça veut dire qu'après
une panne on dispose seulement d'un sous-graphe du graphe architecture.
Le placement résultant dans ce cas-ci est le placement réduit
au niveau du sous-graphe. On dit donc que l'apparition de cette panne est
toléré par le placement si et seulement si le placement réduit
est correct par rapport à l'algorithme, c'est-à-dire par
rapport aux contraintes de placement mentionnées ci-dessus.
On appelle aussi modèle des pannes un ensemble quelconque
des apparitions des pannes. Un exemple de modèle des pannes est
l'ensemble qui comprend toutes les apparitions des pannes qui représentent
des sous-graphes qui résultent après l'élimination
de n processeurs et k média de communication.
Mais la définition peut être adaptée pour prendre en
compte d'autres situations, par exemple le cas où la panne d'un
certain processeur (un actionneur) ne peut pas être tolérée
(voir la discussion sur les pannes des capteurs et actionneurs).
L'heuristique est composée de deux phases :
dans la première phase on prend en compte chaque sous-graphe
dans le modèle des pannes et on applique l'heuristique de SynDEx
pour placer l'algorithme sur ce sous-graphe. Notons que l'on place l'algorithme
sans
répliquer aucune opération à cette phase.
dans la deuxième phase, à partir de tous ces placements
simples on construit un placement avec répliques. L'heuristique
qu'on applique est une modification de l'heuristique de SynDEx, étant
toujours une heuristique « gloutonne » (greedy) qui cherche,
chaque fois qu'on essaie de placer une nouvelle opération, de placer
l'opération qui rallonge le moins possible le chemin critique dans
le graphe de l'algorithme. Bien sûr, la notion de chemin critique
est redéfinie pour prendre en compte le fait qu'on a plusieurs répliques
de chaque opération.
L'heuristique proposée est complète, c'est-à-dire
elle donne un placement si et seulement si l'algorithme peut être
placé de telle manière que chaque apparition des pannes est
tolérée. L'heuristique est aussi flexible : on peut modifier
le critère sur lequel on regroupe les pannes acceptables sans changer
l'heuristique. Un point faible de cette heuristique est la complexité
surexponentielle par rapport à la taille de l'architecture. La conséquence
est que sur les architectures très complexes (des centaines des
processeurs) et pour des modèles de pannes qui comprennent des grandes
parties du graphe de l'algorithme, le temps d'exécution de l'heuristique
peut être prohibitif, à cause de la prise en compte de chaque
possibilité d'apparition de pannes dans la première phase.
Une direction de recherche que l'on peut envisager pour éviter de
prendre en compte chaque apparition de pannes est proposée par Fabien
: c'est l'idée de chercher une certaine régularité
dans le modèle des pannes, régularité qui permet de
faire un seul placement sur l'apparition générique d'une
panne, placement qui est simplement copié sur toutes les autres
apparitions des pannes.
Discussion sur le problème de la génération du code
à partir d'un placement avec des répliques
Catalin et Thierry discutent sur la méthode appliquée dans
SynDEx pour la génération de code et l'adaptation de cette
méthode pour le cas des répliques. La méthode de SynDEx
consiste à projeter chaque transfert de données qui se trouve
placé sur un média multipoint sur chaque processeur qui est
connecté à ce média. Les projections sont nécessaires
à cause du mode de diffusion dans lequel les transferts de données
sont faits, et donc l'identification du message utile pour chaque processeur
se fait à partir de la position de ce message dans la séquence
des messages qui circulent sur le média. Cela veut dire qu'une opération
de transfert des données entre deux processeurs va créer
sur le troisième processeur (en fait sur le coprocesseur dédié
a ce média) un opération consommatrice de synchronisation
qui reçoit les données transmises, mais qui ne va pas les
utiliser pour aucun calcul. On appelle cette opération sync
dans la nouvelle version SynDEx.
Catalin argumente que le problème est que l'apparition d'une
panne peut modifier l'ordonnancement : certaines opérations de transfert
des données peuvent disparaître seulement à cause du
fait que le processeur émetteur est tombé en panne. Thierry
et Catalin se mettent d'accord que sur le code généré
à partir d'un placement avec répliques : des syncs
qui seront exécutés sous le contrôle d'un chien de
garde doivent être ajoutés. Le chien de garde d'un
sync
- disons le n-ième sync dans la séquence des transferts
sur le média - compte la date la plus tard d'exécution du
n-ième transfert des données. Catalin va étudier le
problème de modéliser cette solution et les implications
sur le calcul des valeurs des chiens de garde (voir le
compte rendu précédent).
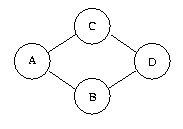
Le problème peut-etre envisage sur l'exemple suivant: on veut placer
l'algorithme ci-dessous sur l'architecture à droite.
 ;
; 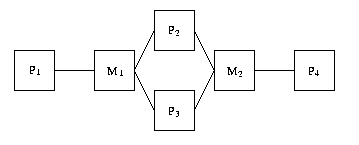
Les contraintes sont les suivantes:
-
L'opération A peut être exécutée seulement sur les processeurs P1 et/ou
P4.
-
L'opération D ne peut s'exécuter que sur le processeur P3.
-
On veut tolerer une seule panne des processeurs P1,P2,P3 ou des media M1,M2
Á observer que on ne veut pas tolérer aucune panne sur le processeur P3.
L'intuition est que celui ci est un actionneur dont l'action ne peut pas être
répliquée (par exemple un moteur sur une axe).
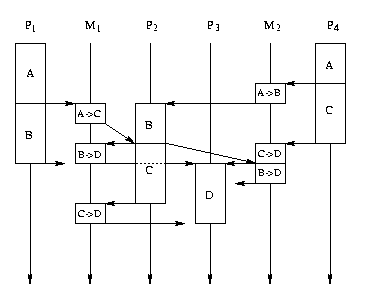
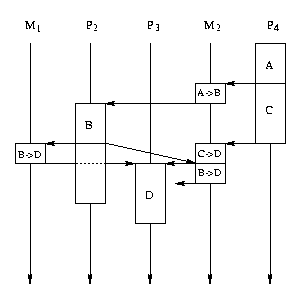
Un placement tolérant à une telle panne est dessiné ci-dessous:
 ;
;  ;
; 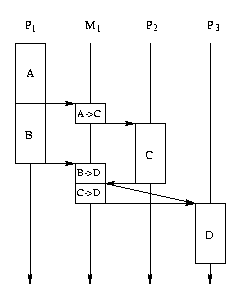
À gauche on observe l'ordonnancement quand il n'y a des pannes, au milieu
l'ordonnancement quand le processeur P1 est tombé en panne et à droite
l'ordonnancement quand M2 tombe en panne (et donc P4 est decoupé du reste
de l'architecture et son ordonnancement n'est plus representé).
Sur cet exemple on peut observer les prochaines faits:
-
Sur l'ordonnancement sans pannes la communication sur le média M1 qui est
utile a l'opération D est la deuxième, mais sur l'ordonnancement avec la
panne du P1 cette communication est la première. Donc P3 (ou plutôt le
coprocesseur de P3 qui le connecte sur le média M1) a besoin d'une méthode
qui lui permet de décider laquelle communication lui est utile.
-
Sur l'ordonnancement avec la panne du média M2 c'est la réplique de l'operation
B sur P1 qui envoie son resultat vers l'opération D, donc le coprocesseur
du P1 qui le connecte sur le média M1 a besoin d'une méthode qui lui permet
de décider s'il est son tour à envoyer les résultats de B ou ces résultats
ont été déjà envoyés.
Les solutions qu'on envisage sont ainsi:
1. Pour le premier problème:
-
soit on transforme le média multipoint telle qu'elle produit seulement
des communications point-a-point, i.e. on emploie un protocole de résolution
d'adresse,
-
soit on place sur chaque coprocesseur connecté à un média multipoint des
operations de synchronisation qui ne font que "tenir compte" des tous
les communications qui s'exécutent sur le média pour decider laquelle est
la communication utile au processeur. En ce cas-ci, la disparition d'une
communication - comme dans le cas du panne du P1 - est "observée" par le
coprocesseur à l'aide d'un chien de garde (watchdog).
2. Pour le second problème les solutions sont paralleles au ci-dessus:
-
soit on emploie, sur chaque coprocesseur, un protocole style "premier arrivé,
premier servi" qui permet au coprocesseur d'envoyer ses donnees s'il n'y
a pas d'activité sur le média ou, en cas contraire, d'observer l'activite
sur le media et, si un autre processeur a deja envoyé les resultats que
le coprocesseur lui-meme doit les envoyer, de renoncer à envoyer ces resultats,
-
soit, pour chaque étape de communication qui peut être assigné au plusieurs
operations - comme le cas de l'étape B->D sur le média M1, qui dans le
premier cas est execute sur commande du coprocesseur du P2 et dans le second
cas sur commande du coprocesseur du P1 - on établit une liste des priorites
sur les processeurs qui concurent pour commander cette communication et
on calcule des timeouts pour chaque d'entre ces processeurs, timeouts qui
permettent de reordonnancer cette liste en cas qu'un processeur n'a pas
reussi d'envoyer ses resultats (car il est en panne ou à cause d'une panne
dans ses predecesseurs).
Calendrier de travail
Le calendrier n'est pas encore fixé. Il va être discuté
dans les prochains jours.
Envoyez vos commentaires à Alain
Girault à Alain.Girault@inrialpes.fr.
Dernière modification : 19 avril 2000
 Retour
à la page d'accueil de l'action TOLÈRE
Retour
à la page d'accueil de l'action TOLÈRE